
Unlocking Legal Knowledge with Multi-Layered Embedding-Based Retrieval
Written on June, 2024

This publication is part of the book “Artificial Intelligence in Legislative Services: Principles for Effective Implementation”. To download the entire book, use the button below:
This work addresses the challenge of capturing the complexities of legal knowledge by proposing a multi-layered embedding-based retrieval method for legal and legislative texts. Creating embeddings not only for individual articles but also for their components (paragraphs, clauses) and structural groupings (books, titles, chapters, etc), we seek to capture the subtleties of legal information through the use of dense vectors of embeddings, representing it at varying levels of granularity. Our method meets various information needs by allowing the Retrieval Augmented Generation system to provide accurate responses, whether for specific segments or entire sections, tailored to the user’s query. We explore the concepts of aboutness, semantic chunking, and inherent hierarchy within legal texts, arguing that this method enhances the legal information retrieval. Despite the focus being on Brazil’s legislative methods and the Brazilian Constitution, which follow a civil law tradition, our findings should in principle be applicable across different legal systems, including those adhering to common law traditions. Furthermore, the principles of the proposed method extend beyond the legal domain, offering valuable insights for organizing and retrieving information in any field characterized by information encoded in hierarchical text.
Introduction
The increasing volume and complexity of legal corpora pose significant challenges for legal professionals, including those in legislative consultancy, where the efficient access and analysis of legal texts are critical. Traditional keyword-based search methods often fall short in capturing the nuances of legal language and the intricate relationships within legal documents (Saravanan et al., 2009; Mimouni, et al. 2014).
Recent advancements in Generative Artificial Intelligence (GenAI) and Retrieval Augmented Generation (RAG) systems offer promising avenues for more efficient and accurate legal information retrieval. Embeddings, which are dense and compact vector representations of text, effectively capture the meanings of words, phrases, or documents (Yu & Dredze, 2015; Chersoni et al, 2021). Legislative documents, including bills and legal normative statutes, inherently have a hierarchical structure. This intrinsic hierarchy calls for an approach with variable granularity, capable of representing both smaller segments and broader groupings of legal texts through embeddings.
This chapter proposes a multi-layered embedding-based retrieval method that captures the semantic content of legal texts. By creating embeddings for articles, their components, and their structural groupings, we aim to provide a more nuanced and comprehensive representation of legal knowledge. Our proposed approach enables RAG models to respond to user queries with varying levels of detail, ranging from small portions to comprehensive sections.
Fundamental Concepts
Before moving forward with an exploration of our method and its applications, it’s essential to define the core concepts pivotal to this study: embeddings, aboutness, retrieval augmented generation, and chunking. These foundational elements form the base of our methodology. If you are already familiar with these terms, feel free to skip to the next section. Our goal is to ensure clarity in our discourse for IT analysts and stakeholders within the legal sector alike, who may not be well-versed in this specialized terminology. By clarifying these key concepts, we aim to eliminate any potential knowledge gaps.
Embeddings: At the heart of our approach lie embeddings, dense vector representations of text that encapsulate semantic meanings within documents. These vectors position words, sentences, or entire documents in a multidimensional space, where the spatial proximity between points signifies semantic similarity. This allows us to obtain a measure of the semantic distance between texts (words, sentences or documents). Distant vectors imply the texts that they stand for are dissimilar, while close vectors imply they are similar.
In the legal domain, the intricate subtleties among various terminologies are captured through embeddings, which can be visualized in a two-dimensional or three-dimensional space via a process that reduces the dimensionalities of the original embedding. Let’s examine an example using the fundamental concepts of Wesley Hohfeld’s framework.
Figure 1 provides the source text for each embedding, alongside the resulting vector representations. The textual descriptions define the legal terms ‘Right’, ‘Duty’, ‘Power’, and so on, outlining their correlatives and opposites. These definitions were transformed into dense numerical vectors, as shown in the last column, capturing the semantic essence of each term. The vectors, which are the outcomes of the embedding process, allow for the spatial mapping and analysis of these concepts in a multidimensional vector space.
Figure 1. Hohfeld’s Legal Positions Definitions and Corresponding Embedding Vectors.

Figure 2 represents these embeddings in three dimensions and shows the graph projection using the Plotly library. It was necessary to reduce the original 3,072 dimensions to 3 dimensions using the PACMAP algorithm. The first image shows the projection of legal positions, while the second image details the cosine similarity between these positions and between the positions and two specific questions. In the second image, green outlines show the semantic proximity between opposing and correlated legal positions. Similarly, outlines in blue indicate the close relationship between the two questions in the model and the legal positions they query. For example, for the question ‘What is Legal Immunity?’, the closest vector is ‘Immunity’.
Figure 2. 3D Map of Hohfeld’s Legal Positions and Similarity Matrix

Beyond capturing the contextual meaning of text, embeddings also reflect some syntactic features of documents. Texts that are semantically identical but presented with slight formal variations—such as differences in capitalization or line breaks—result in distinct yet close vectors. This attention to semantic and syntactic features shows how embeddings comprehensively capture a wide range of linguistic nuances.
Moreover, it’s important to challenge the conventional reliance on keyword-based retrieval methods such as TF/IDF (Ayed & Biskri, 2020) or BM25 (Huang & Huang, 2024), which primarily focus on the frequency of term occurrences. Unlike these traditional techniques, embeddings provide a more precise approach by concentrating on the semantic content of texts. This allows discerning the underlying meanings and themes, rather than merely counting words. This semantic focus makes embeddings particularly effective in complex fields like law, where exact terms may vary but the overarching legal concepts and relationships remain consistent.
Before exploring further into the other concepts, one might wonder about the intrinsic nature of an embedding. How does it capture and reflect the essence of the text it represents? This question leads us to a pivotal realization: embeddings can be seen as the digital “aboutness” of the content they encode.
Aboutness: The concept of aboutness refers to the main theme or subject matter addressed by a text. It encompasses entities, concepts, and relationships, and provides a comprehensive overview of its content. Identifying a document’s aboutness is necessary for pinpointing relevant information in response to specific queries, thereby facilitating the precise retrieval of legal information.
In examining the foundational concept of ‘aboutness’, it is valuable to reference Gilbert Ryle’s early analysis of the term in his article “About,” from Analysis in 1933. Ryle differentiates between interpretations of ‘aboutness’, particularly emphasizing the ‘about conversational’ aspect. He articulates that an expression captures the central theme of a conversation if a considerable number of sentences within that conversation either directly use that expression, employ a synonym, or make an indirect reference to the concept it denotes. This occurrence should dominate without a competing expression or referent being more prevalent across the dialogue. Ryle’s viewpoint suggests that ‘aboutness’ serves as a marker for the primary concern within a discourse, indicated through frequent references or mentions, rather than through the mere presence of specific keywords (Ryle, 1933).
This consideration of Ryle’s perspective aids in refining our approach to embedding legal documents. Recognizing ‘aboutness’ as more than a function of explicit text, but rather as a reflection of the thematic consistency across a document, informs our strategy. It acknowledges that the core theme or subject matter of a discourse is not necessarily tied to the explicit repetition of certain terms but is instead often conveyed through varied linguistic mechanisms that signal ongoing engagement with the theme.
Retrieval Augmented Generation (RAG) is a method that enhances response formulation by leveraging data as a foundational source. This technique capitalizes on both traditional access methods and the semantic prowess of embeddings, thus ensuring that the generated responses are not only relevant but also contextually rich. The framework is a structured approach divided into three main phases: Indexing, Retrieval, and Generation.
In the indexing phase, an extensive index is created using a variety of external sources. If employing traditional approaches, several steps are necessary for textual indexing, including processes like text normalization, which encompasses tokenization and stemming, along with the removal of stopwords, to refine the data for enhanced searchability. Alternatively, advanced approaches involve using pretrained language models to produce semantic vectors of texts (embeddings). In both approaches, it is essential to decide on the indexing unit , whether it be the entire document, uniform parts of the document, or other criteria.
The retrieval phase utilizes the index to find information relevant to user queries. In traditional methods, this process looks at term frequency and the presence of specific terms to rank documents. Common techniques such as TF/IDF or BM25 prioritize documents based on how frequently the search terms appear. Conversely, when using embeddings within the RAG framework, this phase includes selecting indexed items based on their semantic proximity to user questions, employing vector similarity techniques such as cosine similarity or Euclidean distance. This advanced approach allows evaluating the semantic nuances of queries, enhancing ranking by closely aligning results with user intentions and the context of the query. The mathematical representation of user queries through embeddings creates a certain language independence in that the same query expressed by similar words (synonyms or near-synonyms), or even in different languages, can achieve similar results.
The generation phase involves creating responses by combining the retrieved information (concatenated chunks as context) with the original user query. This process typically uses a large language model to ensure the response is contextually relevant and reflects the contextual retrieved data accurately.
To move from the broader framework of RAG to the specifics of the indexing phase, we must first focus on the technique of chunking, which plays a key role in organizing and processing text for retrieval.
Chunking: This process involves dividing text into smaller, manageable segments, such as sentences, paragraphs, or specific legal clauses. Segmenting complex documents into parts allows for a granular examination of each segment’s content and its contribution to the document’s overarching meaning, thus facilitating the analysis and processing of intricate legal texts.
Semantic chunking, as practiced in semchunk, offers a method for dividing text into smaller, semantically coherent segments, utilizing a recursive division technique that initially splits text using contextually meaningful separators. This process is repeated until all segments reach a specific size, ensuring each chunk represents a unique thematic or conceptual element. However, this approach overlooks the intrinsic hierarchical organization of legislative texts, which are structured in a complex hierarchy where the systematization of provisions is explicitly defined by the author. While traditional semantic chunking effectively creates manageable segments using only one layer, it overlooks the multitude of layers derived from the hierarchical organization. In other words, it treats all segments on the same level, disregarding the structured organization that defines their legal significance and their interrelations.
A clear grasp of the aforementioned concepts is essential before exploring the specific characteristics of articulated normative texts. The ensuing section will elaborate on how these principles are applied to represent the complex, hierarchical nature of legislative texts, enabling more effective retrieval of legal knowledge.
The Specificity of Legal and Legislative Information
A defining characteristic of legislative texts is an inherent hierarchical structure. It reflects the systematization of legal dispositions, ranging from broad legal areas to specific articles, clauses, and sub-clauses.
In structured normative texts such as constitutions, every detail has substantial semantic importance. Unlike ordinary language, where redundancy and informality are common, constitutions are carefully crafted documents where each word, phrase, and clause is deliberately chosen to convey specific legal meaning and effect. This precision requires a granular approach to information retrieval. Analyzing and representing legal knowledge at varying levels of detail – from individual clauses and sub-clauses to broader articles, chapters and titles – allows us to capture the full spectrum of meaning embedded within these texts.
Figure 3 depicts the organizational structure of legislative documents in Brazil, conforming to the guidelines of Complementary Law No. 95/1998. The highest level is the “Legal Norm” (Norma Jurídica), under which the Main Text (Texto Principal) is the primary body of the document. Optionally, one or more Annex (Anexo) may be included, indicated by a dashed line, suggesting its non-mandatory nature. It is important to note that the number of Annex can vary, ranging from zero to several, indicating the flexibility for including them.
The foundational unit of this framework is the “Article,” which consists of a mandatory “Lead paragraph” (“caput”) and, potentially, one or more “Paragraphs” (“Parágrafo”), indicated by dashed lines to denote their optionality. These “Paragraphs” elucidate details or exceptions pertaining to the “Lead paragraph.” If enumeration is necessary, the lead paragraph or paragraphs can branch into “Sections” (incisos), which may be further divided into “Items” (alíneas), and then into “Subitems” (item) for detailed specificity.
Simple statutes may consist of only articles, but complex statutes and codes group articles into progressively larger units: “Sections [group of Articles]” and “Subsections” are possible components of “Chapters,” which are compiled under “Titles.” These titles are then organized into “Books,” and multiple books can be part of a larger “Part,” reflecting the elaborate nature of legal codes.
Figure 3. Internal hierarchy of a Brazilian statute, detailing its constituent elements.

Figure 4 provides an overview of the hierarchical structure of Title I and Chapter I of Title II of the Brazilian Constitution. It visually represents how the constitutional text is organized, starting from the broadest divisions and narrowing down to specific provisions. Each “Article” serves as a foundational element, with the “Lead paragraph” (caput) stating the principal point. “Sole Paragraphs” (parágrafo único) provide further explanations or stipulations when an article has only one. For detailed enumeration within an article, “Sections” (incisos) break down the content into subsections, each identified by Roman numerals. These sections can further subdivide into “Items” (alíneas), denoted by lowercase letters, and 'Subitems' for the most specific details, though not depicted in this portion of the structure. This systematic approach allows for a clear and organized reading of the constitutional provisions.
Figure 4. Segment of the Hierarchical Structure of the Brazilian Constitution

Figure 5 is an extract from Title I of the Brazilian Constitution, highlighting its hierarchical structure using color-coded annotations. The Document Component layer indicates the beginning of the main text of the Brazilian Constitution, while the Basic Unit Hierarchy layer contains all the Titles, beginning with Title I. The Basic Unit layer delineates Article 1, detailing the core values of the federation such as sovereignty, citizenship, human dignity, social values of labor and free enterprise, and political pluralism. The Basic Unit Component layer focuses on the “Lead paragraph” (caput) of Article 1, which declares Brazil as an indivisible federation and defines its democratic, legal foundation. Lastly, the Enumeration layer specifically identifies enumeration elements like Section III (inciso) of the lead paragraph of Article 1, which underscores ‘human dignity’ as a fundamental principle.
Figure 5. Layers of the beginning of the Brazilian Constitution

Considering their fundamental role in systematizing legal norms and principles, “Articles” are the most suitable unit for initial semantic chunking within legislative texts. As illustrated in Figure 4, applying this approach to Title I of the Brazilian Constitution results in four distinct chunks, each representing an individual article. While this provides a solid basis for analysis, our proposed methodology, detailed in subsequent sections, seeks to further enhance this process. Generating a broader set of chunks for embedding allows us to create a more detailed and complete representation of legal knowledge, ultimately leading to greater accuracy and effectiveness in legal information retrieval.
Building on our understanding of the hierarchical nature of legislative texts, we now present our proposal for a multi-layered embedding-based retrieval method. This approach aims to capture the semantic content of legal documents at various levels of granularity, from entire documents to individual clauses. The following section will outline the specifics of our chunking methodology in the indexing phase and the strategies for filtering chunks in the retrieval phase.
Proposal for Utilizing a Multi-Layered Embedding-Based Retrieval
This section explores our proposed approach, offering recommendations that cover two RAG phases: chunking methodology during indexing and filtering chunks at retrieval.
Chunking methodology during RAG’s indexing phase
Our proposed solution defines the following layers for segmenting the textual content of a legislative or legal document:
Document Level: At the highest level, we generate one embedding for each document. This captures the overarching theme, purpose, and scope of the legal text. This comprehensive vector can then be used to perform automatic classification of the document, aligning it with relevant legal categories.
Document Component Level: This level concentrates on capturing the essence of document components, which can be systematically presented through articles (such as the main text) or depicted using various structures (like tables or unstructured text). Examples encompass the main text and additional texts components such as justifications (in bills) and schedules (in annexes), with each being assigned its own embedding to represent its distinct contribution to the overarching legal context.
Basic Unit Hierarchy Level: Embeddings are also generated for books, titles, chapters, and sections. This captures the broader themes and relationships between groups of articles.
Basic Unit Level: Each article, as a fundamental unit of legal text, receives its own embedding. This captures the specific legal issue addressed by the article and its core provisions.
Basic Unit Component Level: Further granularity is achieved by creating embeddings for the obligatory head or the paragraphs that compose each article. This allows a detailed understanding of the semantics in each legal provision.
Enumeration Level: Further granularity is achieved by creating embeddings for item that are part of an article head or a paragraph. This allows a detailed understanding of the specific details in each legal provision.
By incorporating embeddings at these different levels, we create a multi-layered representation of legal knowledge, enabling RAG models to respond to user queries with varying levels of detail.
To illustrate the granularity achieved by our proposed method, let us consider the example presented in Figure 4. A standard approach using articles as the embedding unit would segment this text into 4 chunks, corresponding to the 4 articles. However, our hierarchical approach yields a much richer representation. At the Document-Level, we have 1 chunk encompassing the entire text. Similarly, the Text Component-Level also produces 1 chunk, as it encompasses the main body of the text. The Article-Level retains the 4 chunks corresponding to the articles, but the Article Component-Level breaks these down into another 25 chunks: 4 lead paragraphs (caputs), 2 sole paragraphs, and 19 sub-sections (incisos). Finally, the Grouping-Level provides 1 chunk representing the single title. In total, our method generates 32 chunks, thus providing a significantly more detailed representation compared to the 4 chunks of the traditional approach.
Figure 5 not only showcases the structure of Title I of the Brazilian Constitution but also reveals an insightful detail regarding Article Component-Level embedding within legal texts. Specifically, when it comes to enumerative elements such as ‘Sections’ (incisos), ‘Items’ (alíneas), and ‘Subitems’ (itens), it is not sufficient to consider their text in isolation. Since each element elaborates on a part of a larger context, it is essential to embed their text within the context of the superior elements up to the level of the ‘Lead paragraph’ (caput) of the article or the paragraph to which they belong. For instance, instead of isolating the phrase “a dignidade da pessoa humana” (the dignity of the human person), the embedded text should read as follows: “[A República Federativa do Brasil, formada pela união indissolúvel dos Estados e Municípios e do Distrito Federal, constitui-se em Estado democrático de direito e tem como fundamentos:] dignidade da pessoa humana”. This method of embedding ensures that the specific provisions are always understood within the full scope of their intended legal framework.
Filter strategy during RAG’s Retrieval phase
The strategy for filtering chunks in the retrieval system utilizes cosine similarity alongside additional parameters to ensure precise and contextually relevant responses. After computing the cosine similarities between the query embedding and each chunk's embedding within the dataset, the results are sorted based on similarity scores, prioritizing the highest values.
The selection process for the chunks includes several critical steps. Firstly, a baseline token count is set, which in this example is 2,500 tokens. This limit helps manage the total volume of text being considered, preventing overly lengthy or unmanageable responses. Additionally, a baseline percentage for similarity deviation, set here at 25%, is used to compare each chunk’s similarity against the highest found similarity. This comparison helps to filter out chunks that are significantly less similar to the query, maintaining a focus on those most closely related in semantic content.
Chunks are also filtered based on their textual boundaries to avoid overlap in the content presented. If a chunk’s textual range is already covered by another chunk with a higher similarity score, it is not included again, ensuring diversity and relevance in the returned results. This helps in maintaining a concise and focused response area. For instance, if “Art. 5, § 1” is retrieved, there is no need to retrieve “Art. 5, § 1, I” because the latter is encompassed by the former.
The final selection of chunks also considers the total number of tokens accumulated thus far against the baseline. After at least seven segments have been chosen, the process of selecting additional chunks continues until the total number of tokens exceeds the baseline threshold or the similarity falls below 25% of the highest similarity found, whichever comes first. This method balances detail and breadth, providing a comprehensive yet focused array of text for response generation and optimizing both the quality and efficiency of the information retrieval process.
To validate the effectiveness of our multi-layered embedding-based retrieval method, we conducted a comparative analysis against the traditional flat chunking approach. This analysis involved visualizing the embeddings and testing the retrieval results using a series of queries about the Brazilian Constitution. The following section presents the results of this comparative study, highlighting the advantages and potential limitations of our proposed method.
Comparative of Flat vs Multi-Layered Chunking Approaches
This section will present a two-dimensional projection visualization of embeddings and demonstrate a test implementation of RAG for the Brazilian Constitution. We will compare flat (divided by articles) and multi-layered chunking approaches. In the second part, we will test the retrieval results of both approaches using six queries about provisions of the Brazilian Constitution.
In this experiment, we employed the text-embedding-3-large model, configured to generate 256-dimensional vectors. To present the data in a comprehensible manner, we reduced these high-dimensional embeddings to a two-dimensional plane using the dimensionality reduction technique (PACMAP). The visualizations were then created using Plotly, the interactive graphing library, to facilitate a clearer understanding of the data structures and their semantic correlations.
Figure 6 showcases a visualization of article embeddings (traditional method of uniform fragments) of the provisions in Brazil’s Federal Constitution, displayed in a two-dimensional space for easier comprehension. Each point represents an article plotted according to its embedding in a simplified two-dimensional space. This offers a broad overview of how each article is positioned relative to others, potentially reflecting their semantic proximity and thematic linkages.
Figure 6. Article Embedding of the Brazilian Constitution (highlighting Article 2)

Figure 7 exemplifies our hierarchical embedding approach, using the same corpus of the Brazilian Constitution text. The visualization in Figure 7 illustrates the hierarchical embedding method's capacity to generate a multitude of proxies—2954 in total—that more precisely correspond to the semantic content of the legal text, unlike the traditional method which produces only 276. The visualization becomes significantly more intricate. It includes embeddings from various levels of granularity, as advocated in this paper. This comprehensive approach incorporates not only the articles but also their components such as paragraphs, clauses, and sub-clauses, as well as their groupings like titles and chapters.
Figure 7. The Hierarchical Embedding of the Brazilian Constitution (highlighting 4th Paragraph of Article 14)

Figure 8 takes a close look at the Article 5 region, such as its numerous clauses and sub-clauses. Given that Article 5 contains over 70 such components, this figure demonstrates the increased density of points surrounding the Article 5 embedding. It illustrates the detailed semantic landscape that emerges when each subdivision is given a distinct representation, underscoring the sophistication of the proposed multi-layered embedding approach. In Figure 6, note that Article 5 is represented by just a single point, whereas in the hierarchical view, it resembles a cluster.
Figure 8. The Hierarchical Embedding of the Brazilian Constitution Article 5 region

When comparing Figures 6 and 8, it becomes evident that the latter, in addition to possessing the vector representing Article 5 in its entirety (purple), also contains dozens of other vectors representing more specific aspects of this article that deals with fundamental rights. This allows the RAG strategy to offer more relevant excerpts in a more concise and consequently, more economical manner, if the question should be answered based in fine grained provisions.
Comparative of Flat vs Multi-Layered Embedding-Based Retrieval
Table 1 presents the questions formulated for a simple comparative test of response retrieval and generation using Multi-Layer (ML) and Flat embedding approaches. In crafting these questions, we aimed to encompass both specific and comprehensive inquiries. Appendix A lists all the devised questions along with descriptive information about the selected chunks and an evaluation of each chunk's relevance to the response, graded from 'essential' through 'complementary' to 'unnecessary'. Additionally, we have included the corresponding responses from the generation phase, accompanied by a brief commentary on each response. In this comparative test, the "gpt-4-turbo-preview" model was used during the generation stage, limiting the output to 1000 tokens and setting the temperature at 0.3.
Table 1. Case Study Questions and Basic Statistics
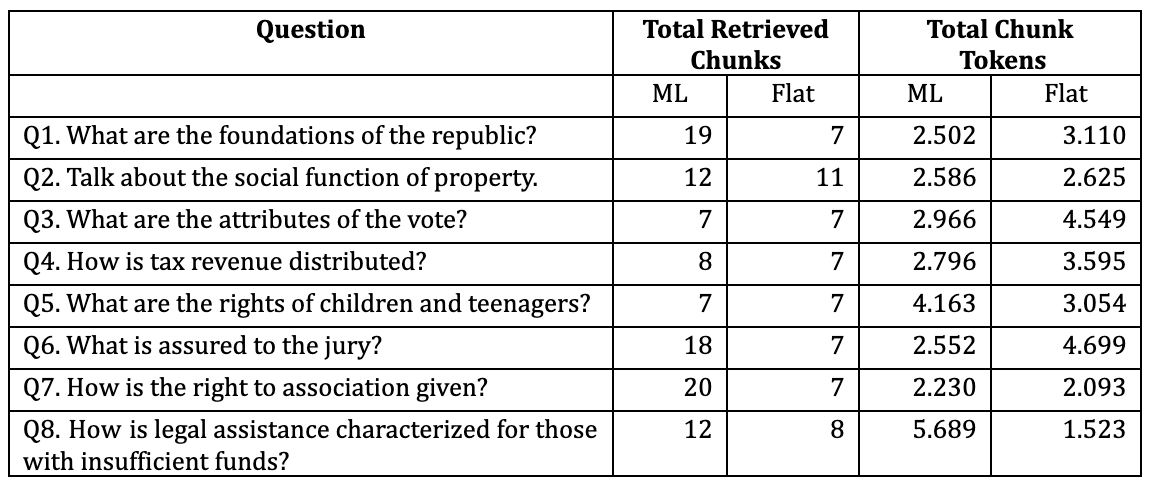
Figure 9 presents a box plot with a comparative visualization of the maximum and minimum similarity scores achieved by two distinct techniques, namely Multi-Layer and Flat chunking approaches, across a series of analytical questions. Each box plot distinctly represents the interquartile range (IQR), medians, thus facilitating a clear overview of the distribution patterns and variance within the data.
Figure 9. Comparison of Max and Min Similarities for ML and Flat Approaches

Upon close examination of the box plot comparing maximum and minimum similarity scores for the Multi-Layer and Flat embedding approaches, it is evident that the Multi-Layer approach tends to exhibit a narrower range at the extremes. This observation is particularly significant as it suggests that the chunks selected using the Multi-Layer embedding are more semantically consistent and closely aligned with the user’s query embedding.
Figure 10 illustrates the classification results of chunks by relevance (color-coded) and also displays cosine similarity between the question and the chunks on the Y-axis. This visualization allows us to observe how quickly the similarity decreases in the sequence of returned chunks. Notably, only in two of the eight cases does the highest similarity chunk coincide between the two chunking methods.
The Multi-Layer technique shows a higher proportion of essential chunks (approximately 37.86%) compared to the Flat Embedding method, which accounts for only about 16.39% of essential chunks. This suggests that the Multi-Layer approach may be better at identifying critical content in the texts, which could be advantageous for applications requiring nuanced understanding of the document's content. Moreover, the Multi-Layer Embedding also has a lower proportion of complementary chunks (around 3.88%) compared to the Flat chunking method (approximately 8.20%). The Flat approach has a significantly higher proportion of chunks classified as unnecessary (about 75.41%) compared to the Multi-Layer Embedding, which has about 58.25% of chunks in this category.
Figure 10. Questions and Chunk Relevance by Chunking Method

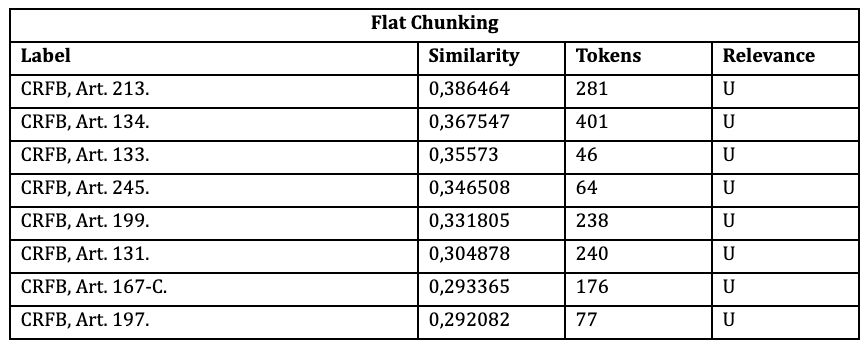
A particular challenge noted in both methodologies, but more effectively managed in the multi-layered approach, is the semantic overload present in Article 5 of the Brazilian Constitution. Questions 6, 7, and 8 (see Appendix) highlight this issue, where the flat embedding struggles to navigate the complex semantic layers within this article. The Article, which covers a broad spectrum of fundamental rights, requires the retrieval system to discern and prioritize among numerous embedded concepts.
Conclusion
The proposed multi-layered embedding-based retrieval approach offers a promising avenue for advancing legal information retrieval. By capturing the inherent structure and diverse granularities of legal knowledge, this method facilitates information access, ultimately empowering legal professionals and researchers in their pursuit of legal knowledge. The method’s ability to represent legal texts at different levels of granularity ensures that whether a query seeks an overview or a detailed examination, the retrieval system can provide the LLM with the relevant chunks as database source to create an answer that matches the user’s specific request.
The flexibility of question embeddings significantly enhances legal searching by permitting queries in plain language or even in different languages, narrowing the divide between legal practitioners and the general public. A legal expert might pose a question in technical terms such as ‘Where does power emanate from?’ (‘De onde emana o poder?’) or in Italian, 'Da dove viene il potere?'. Alternatively, a layperson asking ‘De onde vem a autoridade desse povo que manda?’ (Where do those in power get their authority ?) will receive an equally accurate response. This capability illustrates the system's semantic depth—it prioritizes the collective meaning over individual words.
The comparative evaluation between flat and multi-layered embedding-based retrieval methodologies reveals significant differences in the capacity to recognize and utilize essential text chunks. The flat method often fails to identify critical segments that are crucial for precisely answering queries. This limitation stems partly from its inability to appreciate the full semantic relevance due to the absence of broader contexts and additional layers of information.
In contrast, the multi-layered approach demonstrates a superior ability in identifying and selecting relevant passages, owing to its text analyses at various granularity levels. This not only enhances the accuracy of the responses but also reflects a deeper comprehension of the legal content, facilitating the retrieval of information that is genuinely pertinent to the user's inquiry. Moreover, unlike the flat approach, the multi-layered methodology effectively circumvents redundant or irrelevant chunks, which is critical for maintaining the efficiency of legal information retrieval systems.
In conclusion, the adoption of a Retrieval Augmented Generation (RAG) system with a multi-layered embedding approach can enhance the efficiency and accuracy of legislative consultations. This technology empowers consultants by enabling quicker access to pertinent legal information and facilitating informed decision-making in the drafting and legal analysis of legislation. By streamlining the retrieval and utilization of legal texts, it improves the quality and precision of legislative outputs, fostering a more effective and well-grounded legislative process.
As we look toward future enhancements and expansions of this research, several areas have been identified for further exploration and development.
Inter-Article Relationships: Investigate methods to represent relationships between articles, such as cross-references and dependencies. This could involve creating embeddings for pairs or groups of articles, capturing how they interact and inform each other.
Temporal Dimension: Consider incorporating a temporal dimension into the embeddings, reflecting the evolution of legal texts and amendments over time. This could involve creating embeddings for different versions of the legal text.
Vector Dimensions: During our proof-of-concept tests involving the Constitution we utilized 256 dimensions. Given that the adopted language model is capable of supporting up to 3072 dimensions, future investigations should assess whether increasing the number of dimensions can enhance performance even further. This exploration will help determine if the additional computational cost is justified by potentially improved accuracy and contextual sensitivity in the retrieval of complex legal documents, thus optimizing the trade-off between resource expenditure and retrieval efficacy.
The exploration of multi-layered embedding-based retrieval in legal texts not only enhances the precision of information access but also bridges the gap between complex legal terminologies and the general public’s understanding of them. As we continue to refine and expand upon this methodology, the potential for scalable, linguistically diverse, and contextually rich legal information systems seems increasingly attainable. Future research will undoubtedly unlock further capabilities, making legal knowledge more accessible and navigable for professionals and laypersons alike.
References
Ben Ayed, A.; Biskri, I. (2020). On the Relevance of Query Expansion Using Parallel Corpora and Word Embeddings to Boost Text Document Retrieval Precision. Computer Science and Information Technology, 9, 1-7.
Chersoni, E.; Santus, E.; Huang, C-R.; Lenci, A. (2021). Decoding Word Embeddings with Brain-Based Semantic Features’. Computational Linguistics, 47, 1-36.
De Oliveira Lima, J. A., Griffo, C., Almeida, J. P. A., Guizzardi, G., & Aranha, M. I. (2021). Casting The Light of the Theory of Opposition onto Hohfeld’s Fundamental Legal Concepts. Legal Theory, 27(1), 2–35.
Huang, Y., & Huang, J. (2024). A Survey on Retrieval-Augmented Text Generation for Large Language Models. arXiv preprint arXiv:2404.10981.
Mimouni, N.; Nazarenko, A.; Paul, È.; Salotti, S. (2014). ‘Towards Graph-based and Semantic Search in Legal Information Access Systems’. International Conference on Legal Knowledge and Information Systems.
Ryle, G. (1933). 'About'. Analysis, 1(2), 10-12.
Saravanan, M.; Ravindran, B.; & Raman, S. (2009). ‘Improving legal information retrieval using an ontological framework’. Artificial Intelligence and Law, 17, 101-124.
Yu, M.; Dredze, M. (2015). ‘Learning Composition Models for Phrase Embeddings’. Transactions of the Association for Computational Linguistics, 3, 227-242.
Appendix – Questions
Question 1. What are the foundations of the republic?




Key: E – Essential; C – Complementary; U – Unnecessary
Question 2. Talk about the social function of property.

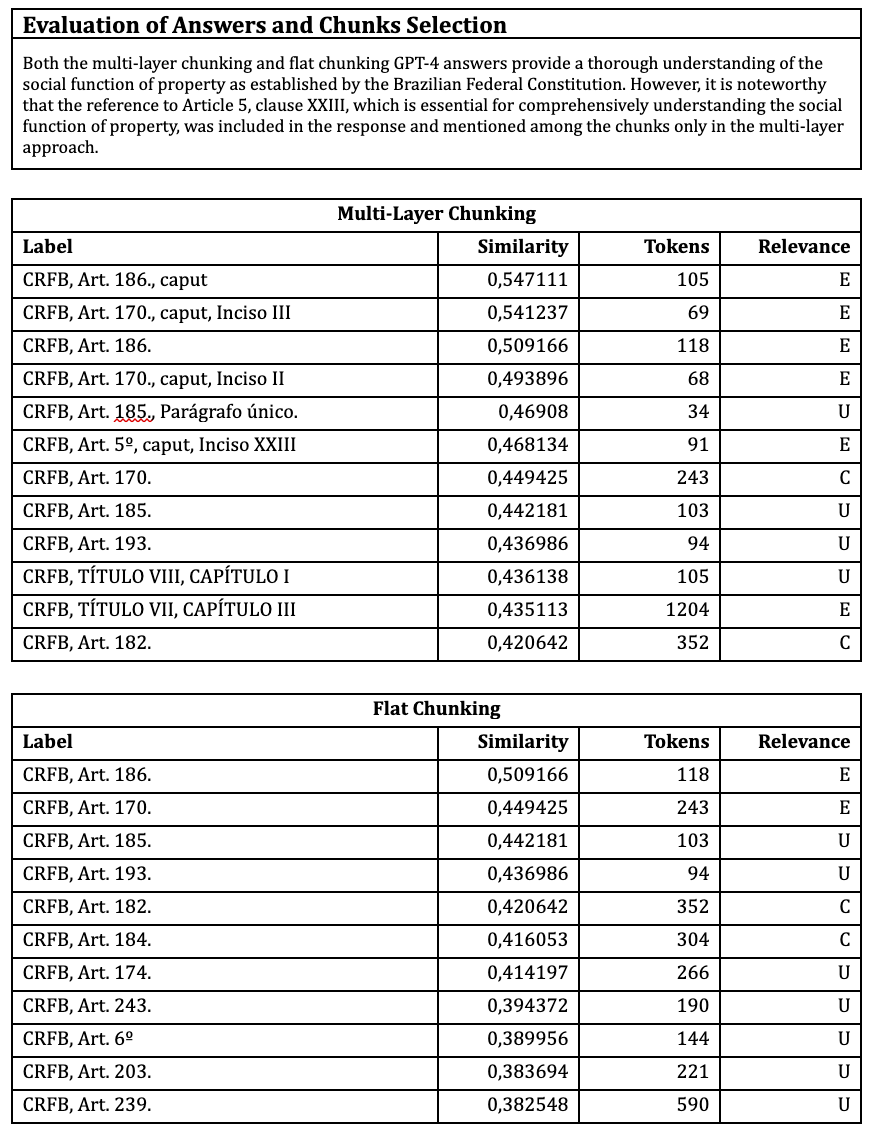
Key: E – Essential; C – Complementary; U – Unnecessary
Question 3. What are the attributes of the vote?


Key: E – Essential; C – Complementary; U – Unnecessary
Question 4. How is tax revenue distributed?

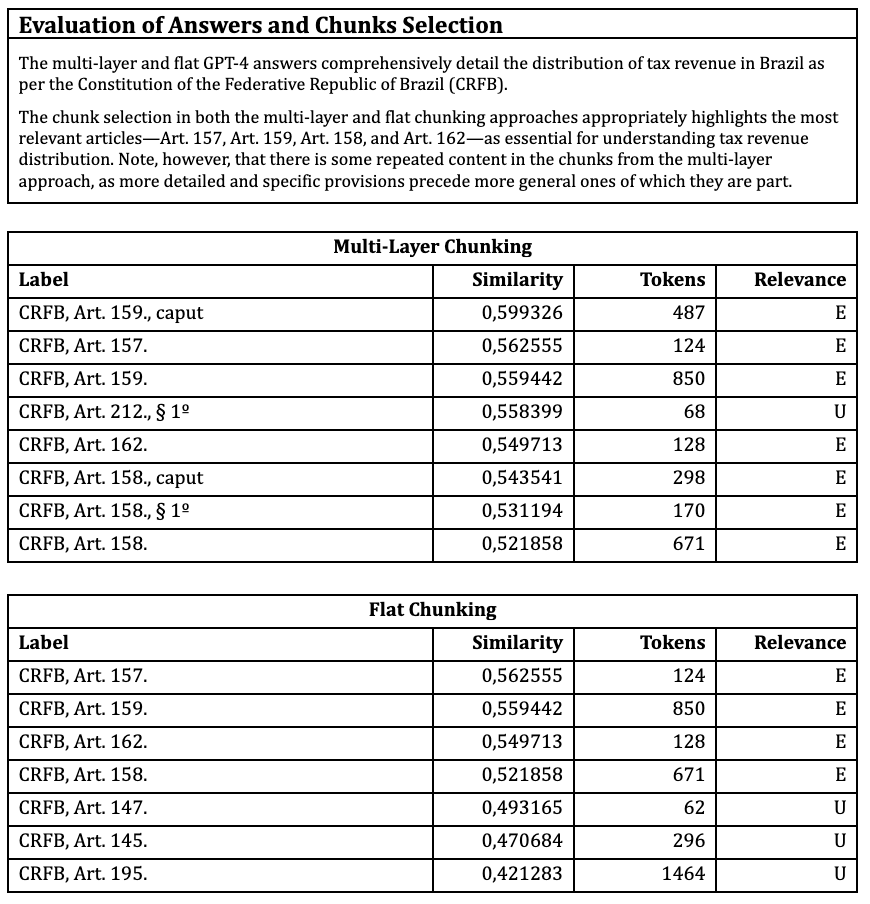
Key: E – Essential; C – Complementary; U – Unnecessary
Question 5. What are the rights of children and teenagers?


Key: E – Essential; C – Complementary; U – Unnecessary
Question 6. What is assured to the jury?
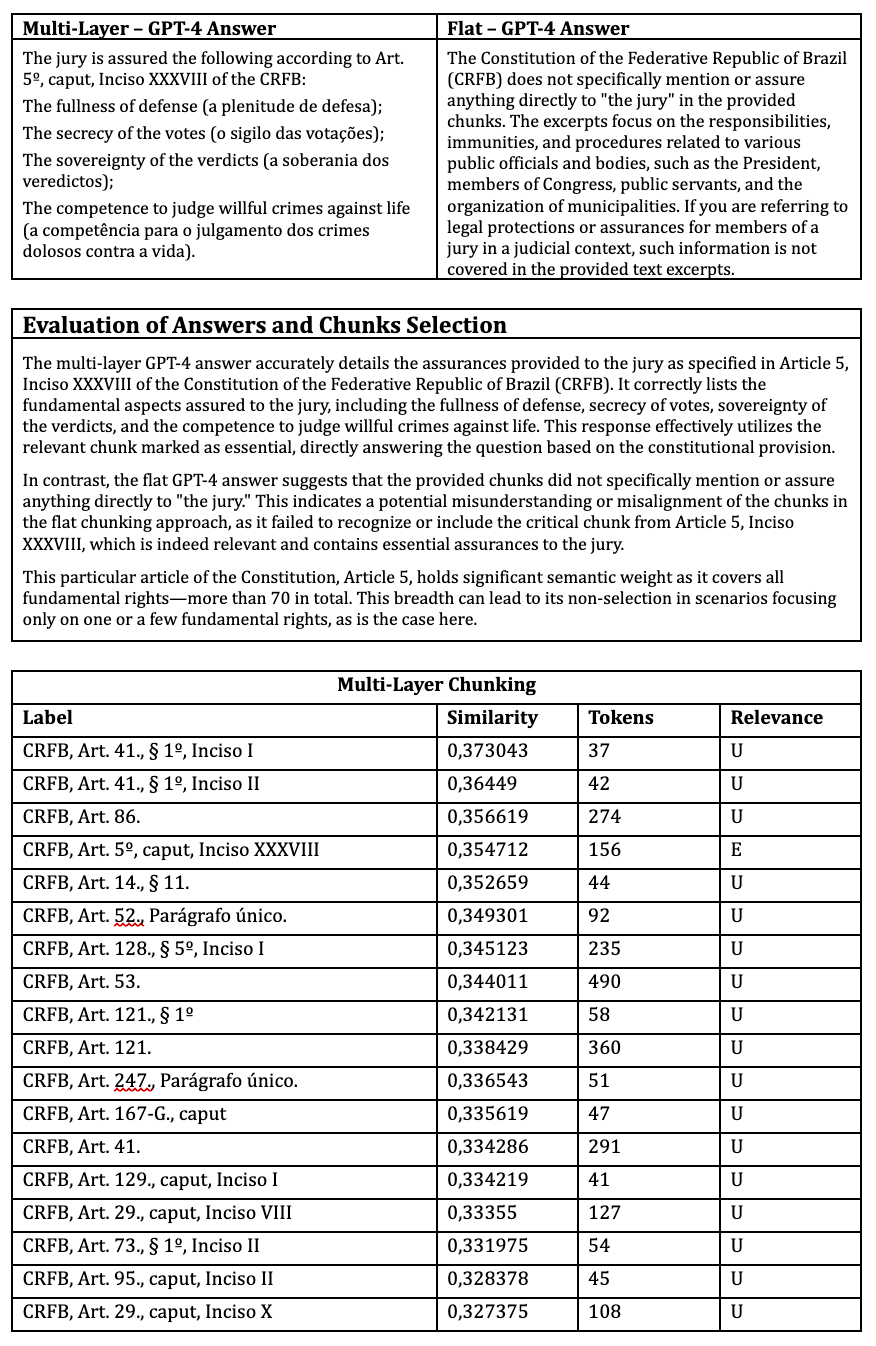

Key: E – Essential; C – Complementary; U – Unnecessary
Question 7. How is the right to association given?
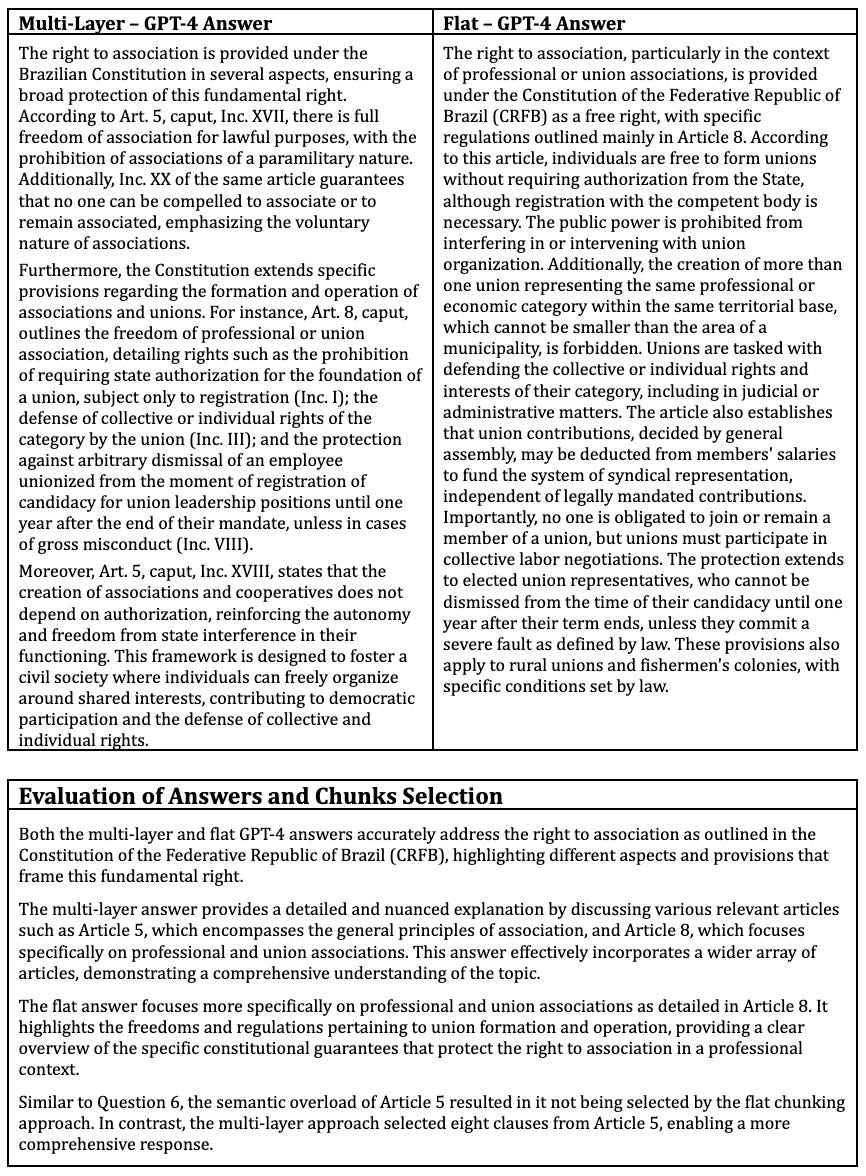

Key: E – Essential; C – Complementary; U – Unnecessary
Question 8. How is legal assistance characterized for those with insufficient funds?

Key: E – Essential; C – Complementary; U – Unnecessary
The views expressed in this article are derived from the analysis of the author and do not necessarily reflect the official policy or position of the represented institutions, nor should they be considered and should not be construed as an endorsement or recommendation of any kind. The information presented in this article is derived from multiple sources. We encourage readers to access official sources from the institution in question.
 | A guest post by
|